A better way of linking to web content
How the web and it’s underlying technologies work is often not entirely obvious to everyone. It’s easy to take things for granted. In this post I’ll explain how linking on the web currently works, and a new better way to do linking on Web 3 – the next version of the web.
Linking on the current web
Firstly, a HTTP link is needed. Most often such a link is embedded on a web page in the form of an HTML anchor with a hyperlink reference value like this: https://example.com/foobar/
Let’s break this down. At the beginning comes the protocol “https” that tells the web browser what to do with the link. What follows is the domain name “example.com” and the path “/foobar/”. Thanks to the Domain Name System (DNS) the domain name resolves to an IP address which points to a specific web server on the Internet. When the request arrives at the web server it’s up to the server to respond with whatever content it finds most appropriate for the given path. In this request flow there are two middle-men (1) the DNS server and (2) the web server. For the user these two middle-men are essentially black boxes that the user needs trust completely. There’s no practical way to know if two users with similar requests are served the same content.
Companies often abuse this trust and modifies content for different users, like when Facebook experimented with users’ emotions. Of course, this technique can also be used for a less evil purpose, i.e. making your page requests more personalised. But personalisation can be done in different ways without compromising on trust (but more on that in another post).
Further, there’s another issue with this kind of infrastructure, namely man-in-the-middle attacks. In such an attack a malicious user takes control of either the DNS server or the web server and serves unauthentic content, perhaps stealing private information submitted by the user.
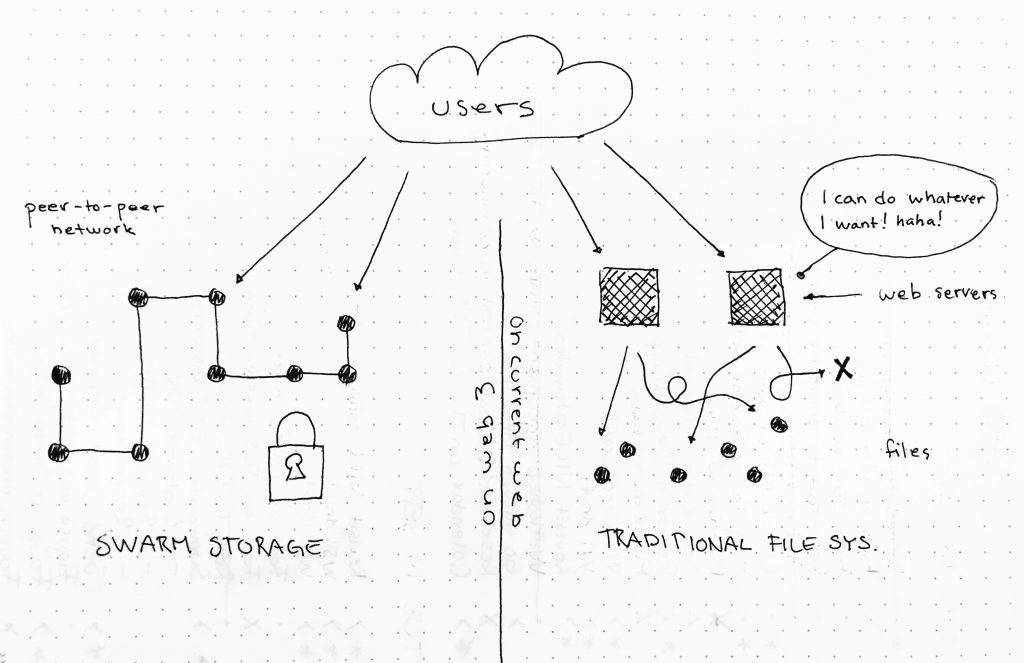
Linking on Web 3
Huh, what’s “Web 3”? This is a new kind of web being built on decentralised infrastructure without any middle-men. It’s different from “the Internet” as we know it. It’s a safer web, where the trust is moved away from central black-box servers to code and infrastructure that is fully transparent and tamper-proof thanks to advanced cryptography. Web 3 is built on technology like Ethereum for content processing, and Swarm for content storage.
So how does linking work on Web 3? In many ways it’s similar to linking on the the current web. We need a HTML anchor link with a hyperlink reference value, but it looks slightly different: bzz://example.eth/foobar/.
In short, the domain and path resolves to the cryptographic hash of the content, which is also the addressed location on the decentralised network. The hash and the location is essentially the same thing. With this you get a cryptographic guarantee that you’re being served the authentic content. While the link resolves to the same hash, the content will never ever change. It’s only when the link is updated to resolve to a different hash that the served content changes. And this is transparent to the user, which is a good thing. The trust is shifted from black-box servers to auditable smart contracts that can not be tampered with.
In more detail, you can see that this new type of link is using a new protocol, namely “bzz”. This tells the web browser that the link works different compared to a “https” link. Using the Ethereum Name Service (ENS) the browser looks up what smart contract that is responsible for resolving the name “example.eth”. This smart contract resolves to the cryptographic hash of a manifest file, that in turn links to hashes of content, which is a explicit guarantee of exactly what content is intended to be served. The manifest file for the “example.eth” root could look like this:
{
"entries": [{
"path": "foobar/",
"hash":"8bgeb0f63ef673491338d4c8ecd8997a7456397cd1c3f2774dc216740c9e5e9e",
"contentType": "text/html"
}]
}
As mentioned earlier, any given hash is always guaranteed to link to its authentic original content. For a given hash it’s not possible to alter the content. This also means that all previous versions of a web page will forever continue to exists on Web 3. This provides a guaranteed audit trail of all changes ever made on the web.
Summary
On Web 3 we address content by the content itself (i.e. its hash) instead of addressing content by server resource location, where the server sometimes can’t be trusted. This creates a safter web where the trust is shifted from unreliable servers to auditable and tamper-proof smart contracts.